
以口腔专科为突破口构建技术壁垒
推动技术成果的临床转化和商业化

核心技术
医疗视频生成模型MedGen
为推动视频生成在医疗领域实现专业突破,来自香港中文大学(深圳)的FreedomAI团队和深圳自由动脉科技有限公司正式发布首个大规模粒度注释医学视频数据集 MedVideoCap-55K,并在此基础上训练出了首个专注于医学视频生成的模型MedGen。现在,是时候打破“医疗静帧”的局限了!
作为首个医学视频生成模型,MedGen不仅保证了医学内容的准确性,还实现了高质量视频生成,展现了其在手术模拟、医学教育、科普动画与远程会诊等领域的广泛应用潜力。
下游任务数据增强
医疗视频监督任务在手术流程识别、病变检测和诊断辅助等场景中发挥着重要作用,能够辅助医生提高诊疗效率和准确性。然而,当前这类任务普遍面临标注数据稀缺、样本不均衡以及隐私保护等挑战,限制了模型的泛化能力和实际应用效果。利用高质量的合成数据进行数据增强成为提升下游监督模型性能表现的关键手段之一。
我们基于 MedGen 探索了其作为数据增强工具在多种医学视频分类任务中的应用效果,通过将 MedGen 生成的视频与原始训练数据结合,验证了其对下游任务性能的促进作用。

MedGen 和 HunyuanVideo 在三个医学视频监督下游任务中作为数据增强对任务效果提升的对比
开源地址:
· Github:https://github.com/FreedomIntelligence/MedGen
· 论文:https://arxiv.org/abs/2507.05675
· 数据集:https://huggingface.co/datasets/FreedomIntelligence/MedVideoCap-55K
· 模型:https://huggingface.co/FreedomIntelligence/MedGen
· 博客:https://huggingface.co/blog/wangrongsheng/medvideocap-55k
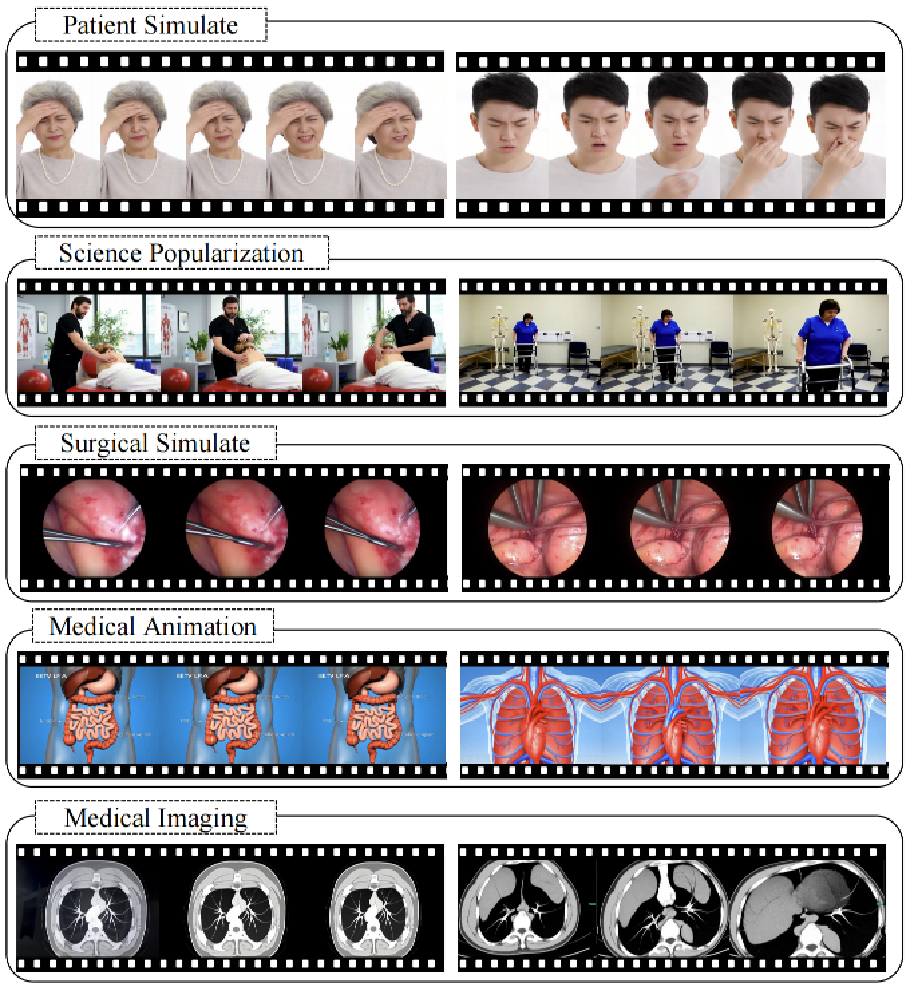
MedGen 在患者模拟、科普教育、手术训练、医疗动画及医学影像等方面的应用
全模态中医理解大模型时珍GPT
单模型融合望闻问切,舌诊脉象气味融会贯通。
首个面向中医全场景的全模态大模型基座——时珍GPT,并开创性地集成了“跨模态统一感知”与“中医知识深植”两大核心能力,让AI首次能像老中医一样,真正看懂舌象、听辨咳音、体察脉息、融合问诊。
· 中医知识丰富:在五项国家级中医考试中,该模型以平均 78.1 分的成绩显著领先同规模开源模型,超越 GPT-4o 和 Doubao-Pro,表现接近 671B 超大模型 DeepSeek-R1,参数效率提升 20 倍以上。
· 视觉诊断精准:在构建的中医视觉基准测试中,该模型以 63.6 分刷新 SOTA,全面优于 GPT-4o、Gemini-1.5、Doubao-Vision。
· 多模态感知精确:脉象妊娠检测、ECG 心律分类、咳嗽音 COVID 检测及心音异常识别的准确率分别为 80.5%、83.1%、58.7% 和 62.9%。
·中医专家认可:在 90 项临床问诊盲测中,医生对时珍GPT 的偏好率显著高于 Doubao/DeepSeek-V3。
开源地址:Github:https://github.com/FreedomIntelligence/ShizhenGPT
论文:https://arxiv.org/pdf/2508.14706
O1慢推理长思考医疗大模型
医疗复杂推理:首个支持长链路医疗复杂推理的医疗大模型,受到业界的广泛关注。


[1] Junying Chen,Chi Gui,Anningzhe Gao,Ke Ji,Xidong Wang,Xiang Wan,Benyou Wang. CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis. https://arxiv.org/abs/2407.13301
[2] Junying Chen,Zhenyang Cai,Ke Ji,Xidong Wang,Wanlong Liu,Rongsheng Wang,Jianye Hou,Benyou Wang. HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs. https://arxiv.org/abs/2412.18925
多模态大模型
多模态大模型-图文:多模态医疗大模型可以应用于病理图像和3D医疗影像的理解,增强诊断的准确性和效率,为医生提供更全面的决策支持。相关模型得到了业界的广泛关注。
多模态大模型-语音:端对端语音理解大模型Soundwave ,在同等规模下性能超过Qwen2-Audio,达到业内领先水平。S2S Arena 是首个面对端对端评测的人工评估平台。

Yuhao Zhang, Fan Bu, Benyou Wang#, Haizhou Li. Soundwave : Less is More for Speech-text Alignment in LLMs.
Feng Jiang, Zhiyu Lin, Fan Bu, Yuhao Du, Benyou Wang#, Haizhou Li. S2S-Arena, Evaluating Speech2Speech Protocols on Instruction Following with Paralinguistic Information.https://huggingface.co/spaces/FreedomIntelligence/S2S-Arena
Fan Bu, Yuhao Zhang, Xidong Wang, Benyou Wang#, Qun Liu, Haizhou Li. Roadmap towards Superhuman Speech Understanding using Large Language Models. https://arxiv.org/abs/2410.13268
多模态大模型-视频:基于医疗视频适配的视频生成模型Medical Sora,利用合成的视频来辅助医疗科普视频生成。通过MedSOSA离线生成医疗科普视频,更加生动直观讲解知识点,提高学习效率和乐趣。

Junying Chen, Rongsheng Wang, Benyou Wang. Towards a medical world simulator. https://medsora.github.io/
多语言大模型
多语言医疗大模型:医疗多语言版本Apollo在多项语言中达到SOTA效果,并且Apollo-2版本现已扩展支持全球50种语言,覆盖全球七十亿人口。 第一代多语言医疗大模型Apollo支持六种语言,覆盖全球60亿人口,第二代Apollo采用MoE结构支持50种语言; 有助于我们开发国外医疗教育市场。
@2x.png)
[1] Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts. Guorui Zheng , Xidong Wang , Juhao Liang, Nuo Chen, Yuping Zheng, Benyou Wang∗. https://arxiv.org/pdf/2410.10626. submitted to ICLR 2025 (score : 8666)
[2] Xidong Wang, Nuo Chen, Junying Chen, Yan Hu, Yidong Wang, Xiangbo Wu, Anningzhe Gao, Xiang Wan, Haizhou Li, Benyou Wang. Asclepius: a Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People. In progress.
[3] Juhao Liang,Zhenyang Cai,Jianqing Zhu,Huang Huang,Kewei Zong,Bang An,Mosen Alharthi,Juncai He,Lian Zhang,Haizhou Li,Benyou Wang,Jinchao Xu. Alignment at Pre-training! Towards Native Alignment for Arabic LLMs. NeurIPS 2024
[4] Jianqing Zhu,Huang Huang,Zhihang Lin,Juhao Liang,Zhengyang Tang,Khalid Almubarak,Mosen Alharthi,Bang An,Juncai He,Xiangbo Wu,Fei Yu,Junying Chen,MA Zhuoheng,Yuhao Du,Yan Hu,He Zhang,Emad A. Alghamdi,Lian Zhang,Ruoyu Sun,Haizhou Li,Jinchao Xu,Benyou Wang. Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion. (meta score of 5, recommended to ACL by AC)
[5] Huang Huang, Fei Yu, Jianqing Zhu, Xuening Sun, Hao Cheng, Dingjie Song, Zhihong Chen, Abdulmohsen Alharthi, Bang An, Ziche Liu, Zhiyi Zhang, Junying Chen, Jianquan Li, Benyou Wang, Lian Zhang, Ruoyu Sun, Xiang Wan, Haizhou Li, Jinchao Xu. AceGPT, Localizing Large Language Models in Arabic. NAACL 2024
多语言大模型技术:研发团队参与阿拉伯语大模型开发,有三千华为昇腾卡训练经验; 三个版本的模型均是开源最好的阿拉伯语大模型。
@2x.png)
[1] Huang Huang, Fei Yu, Jianqing Zhu, Xuening Sun, Hao Cheng, Dingjie Song, Zhihong Chen, Abdulmohsen Alharthi, Bang An, Ziche Liu, Zhiyi Zhang, Junying Chen, Jianquan Li, Benyou Wang# (corresponding), Lian Zhang, Ruoyu Sun, Xiang Wan, Haizhou Li, Jinchao Xu. AceGPT, Localizing Large Language Models in Arabic. NAACL 2024
[2] Jianqing Zhu, Huang Huang, Zhihang Lin, Juhao Liang, Zhengyang Tang, Khalid Almubarak, Mosen Alharthi, Bang An, Juncai He, Xiangbo Wu, Fei Yu, Junying Chen, MA Zhuoheng, Yuhao Du, Yan Hu, He Zhang, Emad A. Alghamdi, Lian Zhang, Ruoyu Sun, Haizhou Li, Jinchao Xu, Benyou Wang#(corresponding),. Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion. (meta score of 5, recommended to ACL by AC)
[3] Juhao Liang, Zhenyang Cai, Jianqing Zhu, Huang Huang, Kewei Zong, Bang An, Mosen Alharthi, Juncai He, Lian Zhang, Haizhou Li, Benyou Wang#(corresponding),), Jinchao Xu. Alignment at Pre-training! Towards Native Alignment for Arabic LLMs. NeurIPS 2024
数据工程和评估
数据构建与模型评估方法:标准中文医疗评估平台CMB上线一年多,有数十家公司和机构参与评测,被收入上海AI Lab的OpenCompass。相关的评测涉及医疗文本、医疗影像、数学推理、数据污染、主观评估、多模态评估、语音等,相关工作被Meta、IBM、google、微软、AIlen AI、CMU、耶鲁、UC Berkeley、商汤、01万物、字节、百川、华为等使用或借鉴。

[1] Xidong Wang,Guiming Hardy Chen,Dingjie Song,Zhiyi Zhang,Zhihong Chen,Qingying Xiao,Feng Jiang,Jianquan Li,Xiang Wan,Benyou Wang*,Haizhou Li .CMB: A Comprehensive Medical Benchmark in Chinese. NAACL 2024. https://cmedbenchmark.llmzoo.com/
[2] Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, Benyou Wang. Humans or LLMs as the Judge? A Study on Judgement Bias. EMNLP 2024. https://aclanthology.org/2024.emnlp-main.474/
[3] Chenghao Zhu, Nuo Chen, Yufei Gao, Yunyi Zhang, Prayag Tiwari, Benyou Wang. Is Your LLM Outdated? Evaluating LLMs at Temporal Generalization. https://arxiv.org/html/2405.08460v2
[4] Ruoli Gan, Duanyu Feng, Chen Zhang, Zhihang Lin, Haochen Jia, Hao Wang, Zhenyang Cai, Lei Cui, Qianqian Xie, Jimin Huang, Benyou Wang. UCL-Bench: A Chinese User-Centric Legal Benchmark for Large Language Models.
[5] Wentao Ge, Shunian Chen, Guiming Hardy Chen, Nuo Chen, Junying Chen, Zhihong Chen, Wenya Xie, Shuo Yan, ChenghaoZhu, Ziyue Lin, Song Dingjie, Xidong Wang, Anningzhe Gao, Zhang Zhiyi, Jianquan Li, Xiang Wan, Benyou Wang. MLLM-Bench: Evaluating Multimodal LLMs with Per-sample Criteria. https://github.com/FreedomIntelligence/MLLM-Bench
[6] Mianxin Liu, Jinru Ding, Jie Xu, Weiguo Hu, Xiaoyang Li, Lifeng Zhu, Zhian Bai, Xiaoming Shi, Benyou Wang, Haitao Song, Pengfei Liu, Xiaofan Zhang, Shanshan Wang, Kang Li, Haofen Wang, Tong Ruan, Xuanjing Huang, Xin Sun, Shaoting Zhang. MedBench: A Comprehensive, Standardized, and Reliable Benchmarking System for Evaluating Chinese Medical Large Language Models. https://arxiv.org/abs/2407.10990
[7] Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, Benyou Wang, Shaoting Zhang, Bin Fu, Jianfei Cai, Bohan Zhuang, Eric J Seibel, Junjun He, Yu Qiao. GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI. NeurIPS Dataset and Benchmak Track 2024.
[8] Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang. MileBench: Benchmarking MLLMs in Long Context. COLM 2024. https://arxiv.org/abs/2404.18532
[9] Fan Bu, Yuhao Zhang, Xidong Wang, Benyou Wang, Qun Liu, Haizhou Li. Roadmap towards Superhuman Speech Understanding using Large Language Models. https://arxiv.org/pdf/2410.13268
[10] Feng Jiang, et.al. Benyou Wang, Haizhou Li. S2S-Bench, Evaluating Instruction Following with Paralinguistic Information in Speech2Speech Scenarios
[11] Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, Xiangyu Yue. AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information? https://arxiv.org/abs/2412.02611
[12] Xuhan Huang, Qingning Shen, Yan Hu, Anningzhe Gao, Benyou Wang. Mamo: a Mathematical Modeling Benchmark with Solvers. https://arxiv.org/abs/2405.13144
模型蒸馏
图灵奖得主Hinton在2015年提出知识蒸馏(Knowledge Distillation)技术,其核心思想是教师模型的输出(软目标)作为额外的学习信号,来训练一个更小、更轻量级的学生模型(Student Model)。Hinton提出的技术方案解决了模型输出层之间的学习,但是隐含层之间的表征学习并没有解决,团队在2020年提出的一种蒸馏技术,是第一个学生模型到老师模型隐含层之间自动映射的技术方案,该方案在实际工程落地上显著降低了项目交付的成本。 我们提出了一种基于Earth Mover's Distance(EMD)的多层对多层映射的模型蒸馏方案。允许student每个中间层根据不同任务自适应地从teacher任何中间层学习。此外,我们还设计了一种cost attention机制,通过自动学习隐含层的权重,来进一步改善模型的性能并加快收敛时间。

[1] Jianquan Li, Xiaokang Liu, Honghong Zhao, Ruifeng Xu, Min Yang, and Yaohong Jin. 2020. BERT-EMD: Many-to-Many Layer Mapping for BERT Compression with Earth Mover's Distance. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3009–3018, Online. Association for Computational Linguistics.